
So sánh DeepSeek R1 và Kimi 1.5: Hai mô hình AI "khủng" ngang tầm "o1-style" từ các pháp sư Trung Hoa
· 6 min read
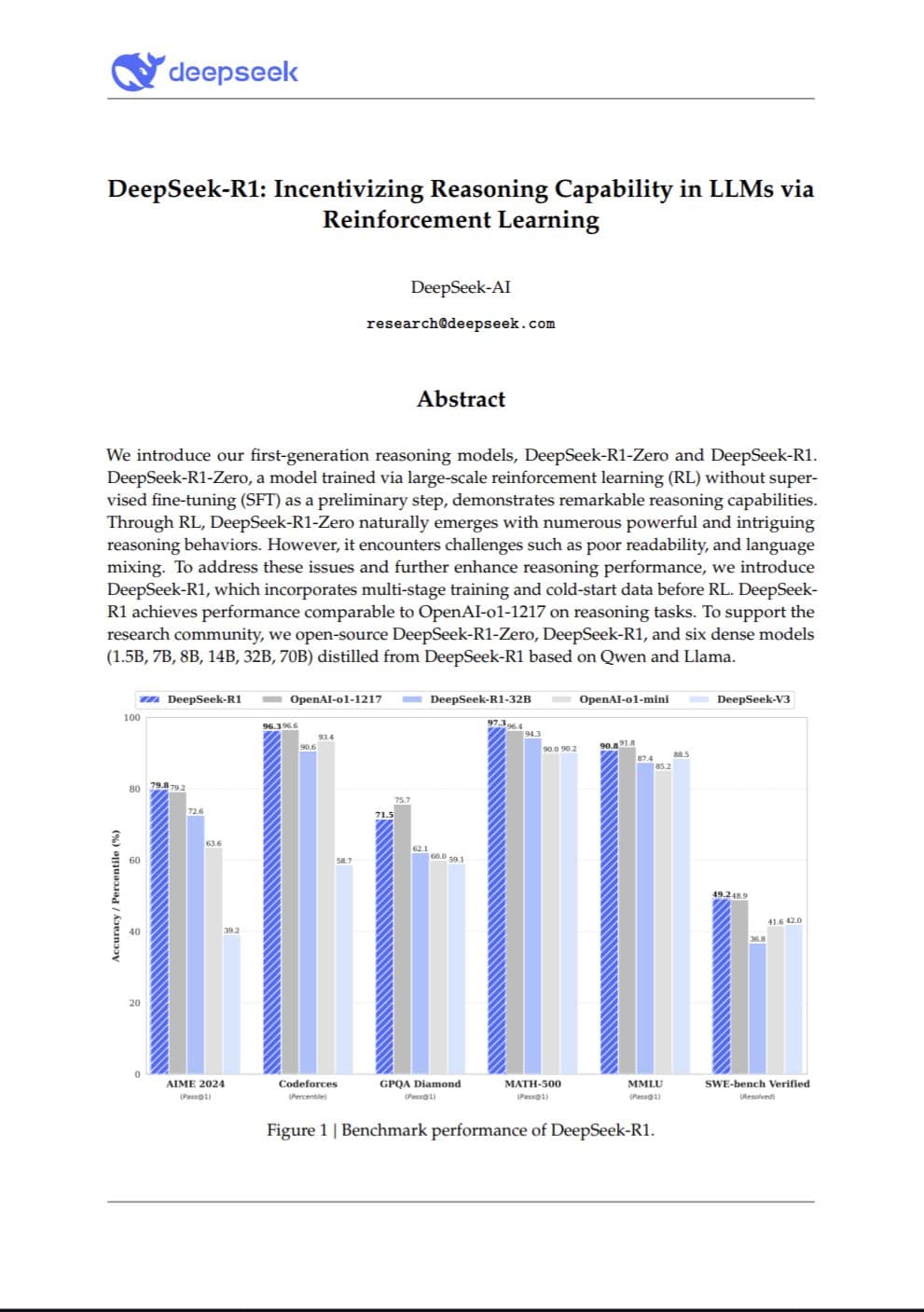
Nguồn: https://arxiv.org/pdf/2501.12948

Nguồn: https://arxiv.org/pdf/2501.12599
1. Ý tưởng chung: Không còn “cồng kềnh” như trước
a) Bỏ Tree Search (MCTS), chỉ cần “nghĩ thẳng một dòng” (linearize)
- Trước giờ: Ta thường thấy AI “chiến” cờ vua, cờ vây dùng MCTS (Monte Carlo Tree Search) để tìm nước cờ ngon. Rất mạnh, nhưng code và tính toán khá phức tạp.
- Giờ: DeepSeek và Kimi đều bảo, “Trên thực tế, ta chỉ cần cho mô hình suy nghĩ theo mạch (chính là Chain of Thought) và dự đoán lần lượt (autoregressive) là đủ.”
- Ví dụ hình dung:
- Giả sử có một cậu bé học cờ vua, thay vì cậu ấy phải vẽ ra cả cái cây quyết định khổng lồ hàng chục nhánh (MCTS), cậu ấy chỉ cần suy luận tuần tự: “Đi tốt lên, đối thủ sẽ làm gì?, Mình phản ứng thế nào?”… cứ thế nối tiếp một đường suy nghĩ ngắn-gọn-mà-trúng.
b) Không cần thêm mạng giá trị (Value Network) cồng kềnh
- Ngày xưa: Trong RL kiểu cũ, ta thường có hai mạng to tướng: một mạng để “ra quyết định” (policy network) và một mạng để “định giá, đo lợi hại” (value network).
- Giờ: Hai nhóm này bảo, không cần phải tách riêng cái value network kia. Vì huấn luyện song song hai “con quái vật” to đùng rất tốn sức (tiền điện, GPU, thời gian…).
- Thực tế: Họ dùng luôn chính mô hình chính (policy) hoặc vài thủ thuật đánh giá đơn giản để thay thế. Thế là tiết kiệm rất nhiều.
c) Tập trung vào kết quả cuối (End Result) hơn là chấm điểm tí tí (Dense Reward)
- Thường thấy: Mọi người thích “chấm điểm” mô hình ở mỗi bước (dense reward) hay dùng “mô hình reward” riêng để phân biệt câu trả lời nào tốt hơn.
- Hai nhóm: Gợi ý “Cứ nhìn chung cuộc xem đúng sai, được hay không” – kiểu như AlphaZero chỉ quan tâm “thắng” hay “thua” cuối. Hạn chế bớt can thiệp chi li, mô hình sẽ học “lối tư duy” một cách tự nhiên hơn (và bớt phức tạp).
- Ví dụ: Học đá bóng, thay vì huấn luyện AI mà cứ 5 giây cho thêm/giảm 1 điểm, ở đây họ bảo “chỉ cần nhìn tỉ số chung cuộc” (thắng thua) là cũng đủ để AI tự rút kinh nghiệm.
2. Sự khác nhau giữa DeepSeek R1 và Kimi 1.5
a) Khởi động (Bootstrapping) khác biệt
- DeepSeek R1:
- “Cold start” kiểu AlphaZero: Tự mày mò từ đầu, không (hoặc rất ít) dữ liệu được “dạy trước” bởi con người.
- Thoạt nghe hơi cực đoan, nhưng nếu chạy lâu, chịu khó “cày” thì có thể đạt level rất cao (như AlphaZero đánh bại AlphaGo).
- Kimi 1.5:
- Dùng “mồi” trước (SFT – Supervised Fine-tuning) kiểu AlphaGo Master: Lấy một ít dữ liệu đã gắn nhãn (ví dụ những “hướng suy luận CoT” do con người soạn) để huấn luyện nhanh buổi đầu, rồi mới chuyển sang RL.
- Kết quả cho thấy mô hình này “lên tay” nhanh hơn, nhất là trong mấy bài toán phức tạp.
b) Cấp độ mở (Open Source) & Giấy phép
- DeepSeek: Công bố toàn bộ trọng số (weights) theo giấy phép MIT – cực kỳ thoáng, ai cũng xài được. Đây là nước đi “chơi lớn” để cộng đồng tha hồ tùy biến.
- Kimi: Hiện chưa phát hành mô hình chính thức. Chỉ công bố paper với nhiều chi tiết kỹ thuật. Ai muốn chạy thử “chính chủ” thì chắc phải… chờ.
c) Tính năng đa phương thức (Multimodal)
- Kimi 1.5 được báo cáo là xử lý tốt nhiều kiểu dữ liệu (văn bản, hình ảnh, biểu đồ, câu đố IQ, hình học…) – họ đưa ra thí nghiệm với MathVista, nơi phải nhìn và hiểu hình rồi giải bài toán.
- DeepSeek chưa đề cập nhiều phần này, hoặc chưa công bố kết quả. Có thể họ đang tập trung vào khía cạnh khác.
d) Chi tiết triển khai: Kimi “kể” nhiều, DeepSeek “kể” ít
- Kimi:
- Paper khá dày, mô tả từ hạ tầng RL (làm cluster, song song ra sao),
- Tới code sandbox (cho mô hình tự viết code, chạy thử, check kết quả),
- Chiến lược nén CoT (vì context quá dài),
- Cách tạo “bài tập” cho mô hình dần khó hơn (curriculum),
- V.v.
- DeepSeek: Không chia sẻ quá sâu về cách họ xây hệ thống, nhưng bù lại mở luôn trọng số để community vọc.
3. Đọc xong, ta rút ra gì?
- RL trên mô hình ngôn ngữ không phải lúc nào cũng cần những cơ chế phức tạp như MCTS, value network hay reward model riêng.
- Cách tiếp cận “tối giản” (simple pipeline) + “dựa vào kết quả cuối” đang được cả DeepSeek và Kimi chứng minh là rất hiệu quả.
- So sánh hai hướng:
- DeepSeek = “tôi tự chơi, tôi tự học, không cần ai nâng đỡ” (AlphaZero style),
- Kimi = “cho tôi tí ví dụ ban đầu để khởi động” (AlphaGo Master style).
- DeepSeek “open” (MIT license), Kimi “kín” hơn về model, nhưng bù lại viết paper rất chi tiết.
- Tương lai, chắc chắn cộng đồng sẽ khai thác hai mô hình (và các ý tưởng của họ) để nâng cấp những LLM hay mô hình đa phương thức khác.
Tóm gọn: Hai nghiên cứu này cho thấy: “Đôi khi cứ làm đơn giản, đừng làm phức tạp là tốt nhất”. Họ đưa minh chứng rõ ràng rằng cắt giảm những module rườm rà (tree search, value net, dense reward) lại cho kết quả tốt bất ngờ, miễn là ta huấn luyện đúng cách. Hơn nữa, việc chia sẻ (hoặc không) trọng số, và cách khởi động RL (có hay không có dữ liệu con người) sẽ quyết định mô hình nào phù hợp với mục tiêu, thời gian, và ngân sách tính toán của từng nhóm.