
Giải Thích Các Khái Niệm Machine Learning/AI Theo Cách Dễ Hiểu Nhất
-Facebook: "https://www.facebook.com/cung.AI.VN/"
Theo gợi ý của admin Nguyễn Tiến Dũng và vài member, tớ chia sẻ 1 vài khái niệm thường gặp trong ML/AI. Qua 1 vài post rất viral và nhiều comment mấy ngày qua về đề tài này trong group, thấy có vẻ nhiều người quan tâm chứng tỏ các chủ đề kỹ thuật cũng khá hot. Lưu ý so sánh nôm na cho dễ hiểu nên có thể không chính xác 100%.
Về cơ bản, ML là bắt chước cách con người học tập. Con người học sao thì máy học vậy!
- 👨🎓 Học sinh vs Mô hình (trong ML hay gọi là "huấn luyện mô hình" nhé!)
- 📚 Bài tập vs Dữ liệu: Muốn người/máy làm gì thì phải cho học/huấn luyện cái đó. Muốn học sinh tính đạo hàm thì phải cho bài tập đạo hàm. Muốn mô hình dự đoán giá nhà thì phải "nhồi" data diện tích, số tầng, vị trí,...
- 🤔 Suy nghĩ, làm bài: Tương tác với dữ liệu: Học sinh nhận bài tập thì suy nghĩ, làm bài. Mô hình nhận dữ liệu thì tương tác với dữ liệu (tùy thuật toán). Kết quả là bài làm của học sinh và dự đoán của mô hình.
- 🧑🏫 Giáo viên & Đáp án: Hàm mất mát (loss function) & Giá trị thực tế (ground-truth): Giáo viên chấm bài dựa trên đáp án. Hàm mất mát đánh giá độ lệch giữa dự đoán của mô hình và giá trị thực tế. Càng lệch ít thì loss value càng nhỏ, mô hình càng tốt.
- 📝 Bài chữa: Giá trị mất mát: Giáo viên chữa bài cho học sinh rút kinh nghiệm. Hàm mất mát trả về loss value để mô hình tự cập nhật và cải thiện.
- 📑 Nhiều bài tập: Minibatch: Học sinh làm nhiều bài tập cùng lúc. Mô hình xử lý một cụm dữ liệu (minibatch) cùng lúc.
- 🔄 Quá trình lặp lại: Bài tập -> làm bài -> chấm bài -> rút kinh nghiệm. Tương tự với máy: Dữ liệu -> tương tác -> dự đoán -> tính loss value -> cập nhật mô hình.
:::note❗ Lưu ý: Học nhiều chưa chắc đã giỏi!** Con người có giới hạn, học đến một mức nào đó thì dù có cố cũng không giỏi hơn được (ví dụ điểm Toán hay TOEIC). Mô hình cũng vậy, huấn luyện đến khi loss value không giảm nữa thì dù có cày thêm cũng không cải thiện được. :::
- 💯 Bài tập chất lượng - Dữ liệu chất lượng: Bài tập phải liên quan và phù hợp với khả năng học sinh. Dữ liệu cũng phải liên quan và phù hợp với khả năng của mô hình.
- 📉 Underfitting: Cho học sinh lớp 12 làm bài đại học thì làm sao làm được? Tương tự, dữ liệu quá phức tạp so với mô hình thì mô hình cũng bó tay, không học được gì.
- 📈 Overfitting: Ngược lại, nếu mô hình quá phức tạp so với dữ liệu thì dễ bị học vẹt, không tổng quát hóa được.
- 🔍Model weight = Học có trọng tâm: Học sinh tập trung nhiều hơn vào những phần kiến thức quan trọng hoặc cần thiết nhất, dựa trên mục tiêu học tập hoặc yêu cầu của kỳ thi. Học có trọng tâm tương tự như model gán trọng số cao cho các đặc trưng quan trọng. Cả người và máy đều tập trung nguồn lực (thời gian, công sức hoặc trọng số) vào những yếu tố có ảnh hưởng lớn đến kết quả cuối cùng.
- 📚 Bias - Học lệch: Do sự đơn giản hóa hoặc tập trung quá hẹp, dẫn đến thiếu hụt kiến thức hoặc khả năng mô hình hóa.
- 🔄 Variance - Học tủ: Do phụ thuộc quá mức vào dữ liệu hoặc kiến thức cụ thể, dẫn đến khó khăn khi đối mặt với tình huống mới.
☝️ Câu chuyện ở trên áp dụng cho mô hình học có giám sát (supervised learning), loại phổ biến nhất trong ML. Mấy loại khác thì hơi khác chút.
- 📝 Token hóa đầu vào - Chuyển lời nói của giáo viên thành văn bản để làm bài: LLMs ‘ghi chép’ bằng cách chuyển đổi văn bản thành các token, giống như học sinh nghe giảng và ghi chép lại để hiểu bài.
- 🧠 Cơ chế Attention - Đọc hiểu trọng tâm: Học sinh khi làm bài sẽ tập trung vào những phần quan trọng của đề bài. LLMs sử dụng cơ chế attention để ‘tập trung’ 🎯 vào các token quan trọng, từ đó hiểu ngữ cảnh tốt hơn.
- 🗣️ Sinh văn bản dựa trên dự đoán từ tiếp theo - Lập luận từng bước, bước sau dựa trên kết quả của bước trước: Học sinh suy nghĩ và viết, câu sau dựa vào câu trước. LLMs dự đoán từ tiếp theo dựa trên các token trước đó, giống như xây dựng lập luận từng bước .
- 💡 Vector Embedding - Dùng mẹo, ví dụ bài thơ có vần để nhớ kiến thức: Học sinh dùng mẹo để ghi nhớ kiến thức. LLMs sử dụng vector embedding để ‘ghi nhớ’ và biểu diễn thông tin, giúp truy xuất thông tin hiệu quả.
Một số khái niệm hay nhầm lẫn:
- ➡️ Lẫn lộn ML và AI - Nhầm lẫn giữa ‘học’ và ‘ứng dụng’: Nhầm lẫn giữa GPT-4 (mô hình ML) và ChatGPT (ứng dụng AI) giống như nhầm lẫn giữa việc ‘học công thức và nguyên lý làm toán’ (ML) với việc ‘ứng dụng kiến thức toán đó để giải bài toán thực tế’ (AI).
- 🔎 ‘Khớp’ (exact match) & ‘Khớp gần đúng’ (fuzzy match) - Tra cứu từ điển & Hiểu nghĩa: Lập trình truyền thống giống như tra từ điển, chỉ tìm kiếm kết quả khớp chính xác. ML giống như hiểu nghĩa của từ, có thể nhận ra các từ đồng nghĩa hoặc gần nghĩa (fuzzy match ví dụ: chó = cẩu, khuyển, dog, chien…). Học sinh không chỉ tra từ điển mà còn phải hiểu nghĩa để làm bài.
- 📚 LLMs & Tìm kiếm - Học sinh & Thi được mở sách: LLMs kết hợp với tìm kiếm giống như học sinh được phép mở sách trong giờ kiểm tra, có thể tra cứu thông tin cần thiết. Nếu không có kiến thức từ trước (LLMs) thì có mở sách cũng không biết chép gì.
- 💾 Lưu trữ kiến thức - Kiến thức nhập tâm: LLMs lưu kiến thức trong weights và biases, chứ không phải lưu trữ trong cơ sở dữ liệu riêng. Giống như học sinh đi thi chỉ lưu kiến thức trong đầu chứ không được mở sách. Cho nên với ML model người ta hay dùng khái niệm ‘Open weight’ chứ không dùng ‘Open source’ (là khái niệm của phần mềm thông thường), hoặc không dùng khái niệm ‘open database’. ‘Open weight’ giống như ‘chia sẻ mẹo học tập’, chứ không như open database là ‘cho chép bài’ .
- 🔄 ‘Tự học’ theo thời gian thực - Ứng dụng kiến thức: LLMs không ‘tự học’ từ tương tác với người dùng vì việc ‘học’ chỉ diễn ra thông qua pre-training, training và fine-tuning dẫn đến kiến thức được nạp vào weight của nó. Sở dĩ nó cung cấp được kiến thức không có trong weight là nhờ khả năng in-context learning từ input của người dùng hoặc thông tin do RAG cung cấp. Đây không hẳn là ‘học’ mà giống như suy luận vì sau khi tắt chat thì kiến thức ‘học’ từ in-context learning cũng bay màu luôn. Kiến thức bền vững là kiến thức model được học trước ngày cut-off date. Muốn cập nhật kiến thức của model thì cần train lại. Giống như học sinh dùng giấy nháp để ghi ra các công thức và tính toán trung gian khi làm toán. Học sinh không 'học' được công thức mới nào, mà chỉ đang áp dụng kiến thức đã có. Sau khi giải xong, tờ giấy nháp bị vứt đi, và bài toán cụ thể với những tính toán cụ thể đó cũng không được vào bộ nhớ.
- 🧠 Vector Embedding & Caching - Nhập tâm & Ghi nhanh ra giấy để khỏi quên: Vector embedding giống như việc học sinh nhập tâm kiến thức. Caching thì khác, nó giống như ghi chú nhanh ra giấy để khỏi quên để dùng lại lúc sau.
- 🤫 Lưu cache phản hồi & Bảo mật - Chia sẻ bài làm & Gian lận: Việc lưu và sử dụng lại phản hồi của người dùng khác là vi phạm quyền riêng tư, giống như việc học sinh gian lận trong học tập cho nhau chép bài.
- 🙅♂️ ‘Lấy dữ liệu của nhau’ - ‘Đạo văn’: LLMs không ‘lấy dữ liệu của nhau’. Nếu có chia sẻ dữ liệu, đó phải là quá trình được kiểm soát và tuân thủ quy định về bảo mật. Giống như học sinh không được phép đạo văn.
CONTEXT WINDOW KHÁC NHAU GIỮA CÁC LLMs - 🧠 GIỐNG NHƯ KHẢ NĂNG NHỚ BÀI CỦA HỌC SINH KHÁC NHAU
- 🧮 LLMs có context window nhỏ - Học sinh chỉ nhớ được ít thông tin: Một số học sinh trí nhớ ngắn hạn kém, khi giải bài toán dài, chỉ nhớ được 2 bước gần nhất. Khi đến bước thứ 3, các em đã quên mất kết quả của bước 1, dẫn đến tính toán sai. Tương tự, LLMs với context window nhỏ chỉ có thể "nhớ" một lượng thông tin hạn chế. Khi lượng thông tin vượt quá context window, mô hình sẽ "quên" những thông tin còn lại (thường là giữa bài), dẫn đến kết quả không chính xác.
- 💪 LLMs có context window lớn - Học sinh nhớ được 10 bước: Ngược lại, một số học sinh có trí nhớ tốt, có thể nhớ được tất cả 10 bước của bài toán và vận dụng một cách chính xác để tính ra kết quả cuối cùng. Tương tự, LLMs với context window lớn có thể xử lý được nhiều thông tin hơn, "nhớ" được ngữ cảnh rộng hơn, từ đó đưa ra câu trả lời chính xác và mạch lạc hơn.
- 👨🏫 Lựa chọn LLM phù hợp - Giao bài toán phù hợp với khả năng của học sinh: Giáo viên sẽ không giao bài toán 10 bước cho học sinh chỉ nhớ được 2 bước. Tương tự, việc lựa chọn LLM phù hợp với từng nhiệm vụ rất quan trọng. Đối với những văn bản dài, cần sử dụng LLMs có context window lớn.
- 🏋️ Tối ưu hóa context window - Rèn luyện trí nhớ: Học sinh có thể rèn luyện trí nhớ để giải các bài toán nhiều bước. Tương tự, các nhà nghiên cứu đang tìm cách để tăng context window của LLMs, giúp mô hình xử lý được nhiều thông tin hơn mà vẫn đảm bảo hiệu suất. Ví dụ Gemini có context window lên đến 2 triệu token.
CHUNKING TRONG RAG - NHƯ HỌC SINH CHIA NHỎ BÀI DÀI ĐỂ HỌC TỪNG PHẦN
- 📚 Chunking - Chia bài dài thành nhiều đoạn nhỏ: Giống như học sinh chia bài dài thành nhiều phần nhỏ để dễ học, chunking là quá trình chia tài liệu lớn thành các đoạn nhỏ hơn gọi là chunk. Việc này giúp LLMs dễ dàng xử lý và tìm kiếm thông tin hơn. Tưởng tượng một quyển sách lịch sử dày cộp, học sinh sẽ không đọc hết một lượt mà chia thành từng chương, từng mục để học.
- 📏 Chunk size - Độ dài của mỗi phần bài học: Chunk size tương đương với độ dài của mỗi phần bài học mà học sinh lựa chọn. Có em thích học theo từng đoạn ngắn, có em thích học theo từng chương dài hơn. Tương tự, chunk size có thể là một vài câu, một đoạn văn, hoặc thậm chí một vài trang, tùy thuộc vào loại tài liệu và mục đích sử dụng. Quan trọng là mỗi chunk phải chứa đủ thông tin liên quan để có ý nghĩa. Giống như học sinh cần học hết một đoạn văn để hiểu được ý chính, chứ không dừng lại giữa chừng.
- 🔍 Tìm kiếm thông tin với chunks - Học sinh tìm kiếm thông tin trong sách giáo khoa: Khi học sinh cần tìm thông tin cụ thể, em ấy sẽ lật từng phần của sách giáo khoa để tìm kiếm. Tương tự, RAG sử dụng chunks để tìm kiếm thông tin liên quan đến câu hỏi của người dùng. Việc chia nhỏ tài liệu thành chunks giúp quá trình tìm kiếm nhanh chóng và hiệu quả hơn. Nếu học sinh chỉ có một quyển sách khổng lồ mà không được chia mục, việc tìm kiếm thông tin sẽ rất khó khăn.
- 🧠 Kết hợp nhiều chunks để trả lời câu hỏi - Học sinh tổng hợp kiến thức từ nhiều phần của bài học: Khi trả lời câu hỏi phức tạp, học sinh cần tổng hợp kiến thức từ nhiều phần khác nhau của bài học. Tương tự, RAG có thể kết hợp thông tin từ nhiều chunks khác nhau để đưa ra câu trả lời hoàn chỉnh và chính xác. Ví dụ, để trả lời câu hỏi về nguyên nhân của một sự kiện lịch sử, học sinh có thể cần tham khảo thông tin từ nhiều chương khác nhau trong sách.
FORWARD PROPAGATION & BACKPROPAGATION - HÌNH DUNG NHƯ HỌC SINH LÀM BÀI VÀ CHỮA BÀI
Forward propagation và backpropagation trong huấn luyện mô hình máy học có thể được minh họa bằng cách học sinh làm bài và chữa bài.
- ➡️ Forward Propagation - Làm bài kiểm tra: Học sinh nhận được đề bài (input data) và bắt đầu làm bài, suy nghĩ và viết ra đáp án (predictions). Quá trình này giống như forward propagation, đưa dữ liệu vào mạng nơ-ron và tạo ra dự đoán.
- 🧐 Backpropagation - Chữa bài kiểm tra: Sau khi làm bài xong, học sinh nhận được bài kiểm tra đã chấm điểm. Hs so sánh đáp án của mình với đáp án đúng (actual values) để tìm ra lỗi sai (calculate the error). Dựa vào những lỗi sai này, Hs rút kinh nghiệm, điều chỉnh phương pháp học tập (adjust model parameters) để làm tốt hơn trong những bài kiểm tra sau (improve accuracy). Quá trình này giống như backpropagation, sử dụng lỗi sai để điều chỉnh mô hình.
- 🔄 Làm bài và chữa bài diễn ra liên tục - Forward propagation và backpropagation phối hợp nhịp nhàng: Hs liên tục làm bài, chữa bài và rút kinh nghiệm để tiến bộ. Tương tự, trong quá trình huấn luyện mô hình, forward propagation và backpropagation diễn ra liên tục và phối hợp nhịp nhàng. Forward propagation tạo ra dự đoán, backpropagation tính toán lỗi sai và điều chỉnh mô hình. Quá trình này lặp lại nhiều lần cho đến khi mô hình đạt được độ chính xác mong muốn.
Ví dụ: Học sinh làm bài toán (forward propagation). Sau đó, giáo viên chữa bài, chỉ ra lỗi sai (backpropagation). Học sinh hiểu lỗi sai và điều chỉnh cách làm để không lặp lại lỗi tương tự trong những bài toán sau.
LOSS FUNCTION & GRADIENT DESCENT - HÌNH DUNG NHƯ HỌC SINH LUYỆN THI
Loss function và Gradient Descent trong Machine Learning có thể được minh họa bằng cách học sinh luyện thi và cố gắng cải thiện điểm số.
- 🎯 Loss function - Chênh lệch giữa điểm của học sinh và điểm tối đa của đáp án: Loss function đo lường mức độ "sai" của mô hình AI so với câu trả lời đúng (ground truth), giống như chênh lệch giữa điểm của học sinh và điểm tối đa của đáp án. Chênh lệch càng lớn thì bài làm càng "sai", giá trị của loss function càng cao thì mô hình càng "tệ". Nói cách khác, loss function đo độ vênh giữa hiệu suất hiện tại của mô hình và hiệu suất hoàn hảo, giống như điểm số đo mức chênh lệch giữa bài làm của học sinh và đáp án đúng.
- 🏃 Gradient Descent - Quá trình học sinh tìm cách cải thiện điểm số: Học sinh muốn cải thiện điểm số sẽ phải tìm ra những điểm yếu của mình, học lại những phần chưa hiểu rõ, luyện tập thêm các dạng bài tập. Học sinh tiến bộ khi thu hẹp khoảng cách giữa điểm số hiện tại và điểm tối đa. Quá trình này giống như Gradient Descent, liên tục tìm cách để có giá trị của loss function thấp nhất, bằng cách thu hẹp khoảng cách giữa giá trị hiện tại của mô hình và ground truth. Giống như khi dùng Google Maps di chuyển, người dùng nhận thấy khoảng cách giữa vị trí hiện tại và điểm đến ngày thu hẹp cho đến khi thấy thông báo "Bạn đã đến nơi".
BỎ QUA VẤN ĐỀ ĐẠO ĐỨC KHI XÂY DỰNG MÔ HÌNH AI - GIỐNG NHƯ HỌC SINH CHỈ HỌC VĂN KHÔNG HỌC LỄ
- ❌ Sai lầm: "Bỏ qua vấn đề đạo đức trong AI" - "Học sinh chỉ cần học giỏi, không cần quan tâm đến đạo đức."
- 🤖 Mô hình AI có thể chứa bias (thiên kiến) - Học sinh có thể bị ảnh hưởng bởi những định kiến xã hội: Giống như học sinh có thể bị ảnh hưởng bởi những định kiến xã hội (vd phân biệt đối xử giới tính, vùng miền...) từ gia đình, bạn bè , môi trường xung quanh, mô hình AI cũng có thể chứa bias từ dữ liệu huấn luyện. Nếu dữ liệu huấn luyện phản ánh những định kiến không công bằng, mô hình AI cũng sẽ đưa ra những kết quả thiên vị.
- ⚖️ Tính công bằng và minh bạch trong AI - Tính công bằng và minh bạch trong giáo dục: Hệ thống giáo dục cần đảm bảo tính công bằng cho mọi học sinh, không phân biệt đối xử. Quy trình đánh giá cần minh bạch, rõ ràng. Tương tự, mô hình AI cần được thiết kế và triển khai một cách công bằng, minh bạch. Cần hiểu rõ cách mô hình hoạt động và ra quyết định.
- 🗣️ Trách nhiệm giải trình trong AI - Học sinh cần chịu trách nhiệm về hành vi của mình: Học sinh cần chịu trách nhiệm về hành vi và lời nói của mình. Tương tự, cần có cơ chế trách nhiệm giải trình cho những quyết định của mô hình AI, đặc biệt là trong những lĩnh vực nhạy cảm như y tế, tư pháp.
- 🧑🏫 Giám sát và điều chỉnh mô hình AI - Giáo dục và uốn nắn học sinh: Học sinh cần được giáo dục và uốn nắn thường xuyên về đạo đức. Tương tự, mô hình AI cần được giám sát và điều chỉnh liên tục để đảm bảo hoạt động đúng đắn và không gây ra những hậu quả tiêu cực.
ĐIỂM CỰC TIỂU CỤC BỘ VÀ TOÀN CỤC TRONG GRADIENT DESCENT - GIỐNG NHƯ HỌC SINH DÙNG GIẢI PHÁP TÌNH THẾ VÀ GIẢI PHÁP TOÀN DIỆN LÂU DÀI
Học sinh thường phải tìm ra cách giải quyết vấn đề trong học tập, đôi khi là giải pháp tạm thời, đôi khi là giải pháp tối ưu. Việc này cũng giống như Gradient Descent tìm kiếm điểm tối ưu, có thể là điểm cực tiểu cục bộ hoặc toàn cục.
- 🔎 Global minimum - Giải pháp toàn diện lâu dài: Học sinh luôn mong muốn tìm ra phương pháp học tập tốt nhất, giúp hiểu bài sâu, nhớ lâu và áp dụng được vào nhiều tình huống. Đây chính là "giải pháp toàn diện lâu dài". Tương tự, global minimum là điểm mà hàm mất mát đạt giá trị thấp nhất, tức là khi mô hình AI hoạt động tốt nhất, một giải pháp tối ưu cho bài toán.
- 🩹 Local minimum - Giải pháp tình thế: Đôi khi, học sinh gặp bài toán khó và chưa tìm ra được cách giải quyết triệt để. Các em có thể dùng giải pháp tình thế, ví dụ như học thuộc lòng công thức mà chưa hiểu rõ bản chất. Giải pháp này có thể giúp vượt qua bài kiểm tra trước mắt, nhưng không bền vững. Tương tự, local minimum là một điểm mà hàm mất mát đạt giá trị thấp, nhưng chưa phải thấp nhất, giống như một "giải pháp tình thế" cho mô hình AI.
- ⚠️ Gradient Descent có thể bị mắc kẹt tại local minimum - Học sinh có thể mắc kẹt với giải pháp tình thế: Nếu học sinh chỉ hài lòng với giải pháp tình thế, các em sẽ không có động lực tìm kiếm giải pháp tốt hơn, dẫn đến việc học tập không hiệu quả về lâu dài. Tương tự, Gradient Descent có thể bị mắc kẹt tại local minimum, không thể tìm thấy global minimum, dẫn đến mô hình AI chưa đạt hiệu suất tối ưu.
- 🚀 Vượt qua local minimum - Học sinh tìm kiếm giải pháp toàn diện: Để đạt được kết quả tốt nhất, học sinh cần nỗ lực tìm tòi, học hỏi và thử nghiệm nhiều phương pháp khác nhau để tìm ra giải pháp toàn diện lâu dài. Tương tự, trong ML, có nhiều kỹ thuật giúp Gradient Descent vượt qua local minimum để tìm global minimum, ví dụ như thay đổi learning rate, sử dụng momentum, hoặc các biến thể khác của Gradient Descent.
ĐÁNH GIÁ MODEL - TƯƠNG TỰ ĐÁNH GIÁ HỌC SINH DỰA TRÊN NHIỀU TIÊU CHÍ
Trong ML, sẽ là sai lầm khi dùng độ chính xác (accuracy) để đánh giá hiệu năng của mô hình giống như chỉ đánh giá học sinh qua điểm bài kiểm tra. Mặc dù điểm số quan trọng, nhưng nó không phản ánh hết năng lực của học sinh.
- 📊 Nhiều metrics khác nhau để đánh giá mô hình - Nhiều cách đánh giá năng lực học sinh: Ngoài điểm số, học sinh còn được đánh giá qua các hoạt động khác như bài tập về nhà, thuyết trình, làm việc nhóm, thái độ học tập,... Tương tự, ngoài accuracy, còn nhiều metrics khác để đánh giá mô hình AI như precision, recall, F1-score, và các metrics chuyên biệt cho từng lĩnh vực như BLEU Score cho xử lý ngôn ngữ tự nhiên.
- 🎯 Lựa chọn metrics phù hợp với từng bài toán - Đánh giá học sinh dựa trên tiêu chí phù hợp với từng môn học: Mỗi môn học có cách đánh giá khác nhau. Ví dụ, môn Văn chú trọng khả năng diễn đạt, môn Toán chú trọng tư duy logic. Tương tự, việc lựa chọn metrics phù hợp với từng bài toán trong ML rất quan trọng. Ví dụ, trong bài toán phân loại spam, recall (khả năng phát hiện tất cả các email spam) quan trọng hơn precision (độ chính xác của việc phân loại spam).
- 🥇 Accuracy cao chưa chắc là mô hình tốt nhất - Điểm cao chưa chắc đã là học sinh giỏi nhất: Học sinh có thể đạt điểm cao trong bài kiểm tra nhưng lại thiếu kỹ năng thực hành, kỹ năng mềm,... Tương tự, một mô hình có accuracy cao chưa chắc đã là mô hình tốt nhất. Có thể mô hình bị overfitting (học vẹt), hoạt động kém với dữ liệu mới, hoặc không phù hợp với ứng dụng thực tế.
- 🤔 Cân nhắc nhiều yếu tố khi đánh giá mô hình - Cân nhắc nhiều yếu tố khi đánh giá học sinh: Giáo viên không chỉ nhìn vào điểm số mà còn xem xét nhiều yếu tố khác như quá trình học tập, sự tiến bộ, khả năng tư duy,... để đánh giá học sinh một cách toàn diện. Tương tự, khi đánh giá mô hình AI, cần cân nhắc nhiều yếu tố như tốc độ xử lý, khả năng mở rộng, mức độ tiêu tốn tài nguyên,...
Tóm lại, việc đánh giá mô hình AI cần phải toàn diện, giống như việc đánh giá học sinh không chỉ dựa trên điểm số. Lựa chọn đúng metrics và cân nhắc nhiều yếu tố khác nhau là rất quan trọng để đánh giá hiệu quả và lựa chọn mô hình phù hợp nhất.
XỬ LÝ DỮ LIỆU: CÔNG ĐOẠN TRƯỚC VÀ SAU - GIỐNG NHƯ HỌC SINH LÀM BÀI
Trong ML, xử lý trước (pre-processing) và xử lý sau (post-processing) cũng quan trọng như việc học sinh chuẩn bị bài và kiểm tra kết quả. Bỏ qua những bước này sẽ ảnh hưởng lớn đến kết quả.
-
✍️ Xử lý trước dữ liệu - Học sinh chuẩn bị bài trước khi đến lớp: Học sinh cần chuẩn bị bài trước khi đến lớp, đọc trước nội dung, gạch chân, ghi chú những điểm quan trọng. Việc này giúp học sinh dễ dàng tiếp thu bài giảng của giáo viên. Tương tự, xử lý trước dữ liệu (tokenization, normalization, data cleaning) giúp làm cho dữ liệu sạch, gọn gàng và phù hợp với mô hình AI. Dữ liệu chưa được xử lý sạch sẽ sẽ làm giảm độ chính xác của mô hình.
-
✨ Xử lý sau dữ liệu - Học sinh kiểm tra kết quả và trình bày bài rõ ràng: Học sinh có kiến thức tốt nhưng nếu không kiểm tra kết và trình bày bài thiếu mạch lạc, khó hiểu thì cũng không được điểm cao. Tương tự, xử lý sau dữ liệu (decoding strategies, output formatting) giúp kiểm tra chất lượng đầu ra để đảm bảo mô hình đưa ra kết quả hợp lý, đúng format yêu cầu. Kết quả không được định dạng đúng sẽ khó sử dụng trong thực tế.
-
❌ Sai lầm: "Tất cả kỹ thuật tối ưu hóa đều áp dụng được như nhau" - "Mọi phương pháp học tập đều hiệu quả như nhau cho tất cả học sinh và mọi môn học."
Trong Machine Learning, việc chọn lựa kỹ thuật tối ưu hóa giống như học sinh lựa chọn phương pháp học tập. Không phải phương pháp nào cũng hiệu quả như nhau cho mọi tình huống.
- ⚙️ Các kỹ thuật tối ưu hóa khác nhau có tác động khác nhau - Cách học khác nhau cho hiệu quả khác nhau: Có học sinh học hiệu quả bằng cách nghe giảng, có học sinh lại thích tự học qua sách vở. Có em học tốt bằng cách làm nhiều bài tập, có em lại học tốt bằng cách hệ thống hóa kiến thức. Tương tự, các kỹ thuật tối ưu hóa mô hình như nén mô hình (model compression), lượng tử hóa (quantization), và cắt tỉa (pruning) có tác động khác nhau đến hiệu suất của mô hình.
- 🤔 Lựa chọn kỹ thuật tối ưu hóa cần cân nhắc nhiều yếu tố - Chọn phương pháp học phù hợp với bản thân, môn học và điều kiện: Học sinh cần lựa chọn phương pháp học phù hợp với bản thân, môn học và điều kiện học tập. Ví dụ, học văn có thể cần phương pháp học khác với học toán. Học sinh có điều kiện học thêm có thể có phương pháp học khác với học sinh không có điều kiện học thêm. Tương tự, việc lựa chọn kỹ thuật tối ưu hóa mô hình cần phải cân nhắc kiến trúc mô hình, yêu cầu nhiệm vụ, giới hạn phần cứng, và mức độ hiệu suất chấp nhận được.
- 🙅 Không có kỹ thuật tối ưu hóa nào là hoàn hảo - Không có phương pháp học tập nào là hoàn hảo: Mỗi phương pháp học tập đều có ưu điểm và nhược điểm. Một phương pháp hiệu quả cho môn này có thể không hiệu quả cho môn khác. Tương tự, không có kỹ thuật tối ưu hóa nào là hoàn hảo cho mọi tình huống. Mỗi kỹ thuật đều có những trade-off riêng.
💯 Tóm lại, việc lựa chọn kỹ thuật tối ưu hóa mô hình cần phải được cân nhắc kỹ lưỡng, giống như học sinh cần phải tìm ra phương pháp học tập phù hợp với bản thân và môn học. Không có "phương pháp thần thánh" nào áp dụng được cho mọi trường hợp. Quan trọng là phải hiểu rõ đặc điểm của từng kỹ thuật và áp dụng một cách linh hoạt.
Giải Nobel vật lý năm nay đã được trao cho hai nhà khoa học John Hopfield và Geoffrey Hinton vì "những khám phá và phát minh cơ bản khởi nguồn cho sự phát triển của ngành học máy với mạng nơron nhân tạo". Các mạng nơ-ron giống như những 'bộ óc digital' trong Machine Learning, giúp máy tính 'học' từ kinh nghiệm và trở nên thông minh hơn sau mỗi lần huấn luyện – giống như học sinh rèn luyện kỹ năng qua từng bài học từ việc nhận diện khuôn mặt, hiểu ngôn ngữ đến dự đoán xu hướng.
PERCEPTRON VÀ DEEP NEURAL NETWORK
- 🧠 Perceptron (Perceptron) - Học sinh học thuộc lòng một công thức đơn giản: Học sinh học thuộc công thức tính diện tích hình chữ nhật: Diện tích = chiều dài x chiều rộng. Perceptron là một mô hình đơn giản, nhận đầu vào, nhân với trọng số (weights), cộng lại và đưa ra kết quả. Nó giống như việc áp dụng một công thức đơn giản đã học thuộc. Perceptron là thành phần cơ bản nhất của mạng nơ-ron, cũng như công thức đơn giản là nền tảng cho các phép tính phức tạp hơn.Perceptron thường dùng trong bài toán phân loại đơn giản.
- 🤖 Deep Neural Network (DNN) (Mạng nơ-ron sâu) - Học sinh giải quyết bài toán phức tạp bằng nhiều bước suy luận: Học sinh giải một bài toán hình học phức tạp, cần vận dụng nhiều công thức và định lý khác nhau, suy luận logic qua nhiều bước. DNN cũng vậy, nó gồm nhiều lớp perceptron xếp chồng lên nhau, cho phép xử lý thông tin phức tạp qua nhiều tầng, từ đó "học" được các đặc trưng trừu tượng và giải quyết các bài toán khó hơn perceptron đơn lẻ. Mỗi lớp perceptron như một bước suy luận, và nhiều lớp kết hợp lại tạo thành một quá trình suy luận phức tạp. DNN giống như học sinh "suy nghĩ sâu sắc" hơn để giải quyết vấn đề. DNN thường dùng trong các bài toán phức tạp như nhận diện hình ảnh, xử lý ngôn ngữ tự nhiên.
Đây là một sơ đồ mô tả ba loại hình học máy cơ bản: Học có giám sát (Supervised Learning), Học không giám sát (Unsupervised Learning), và Học tăng cường (Reinforcement Learning).
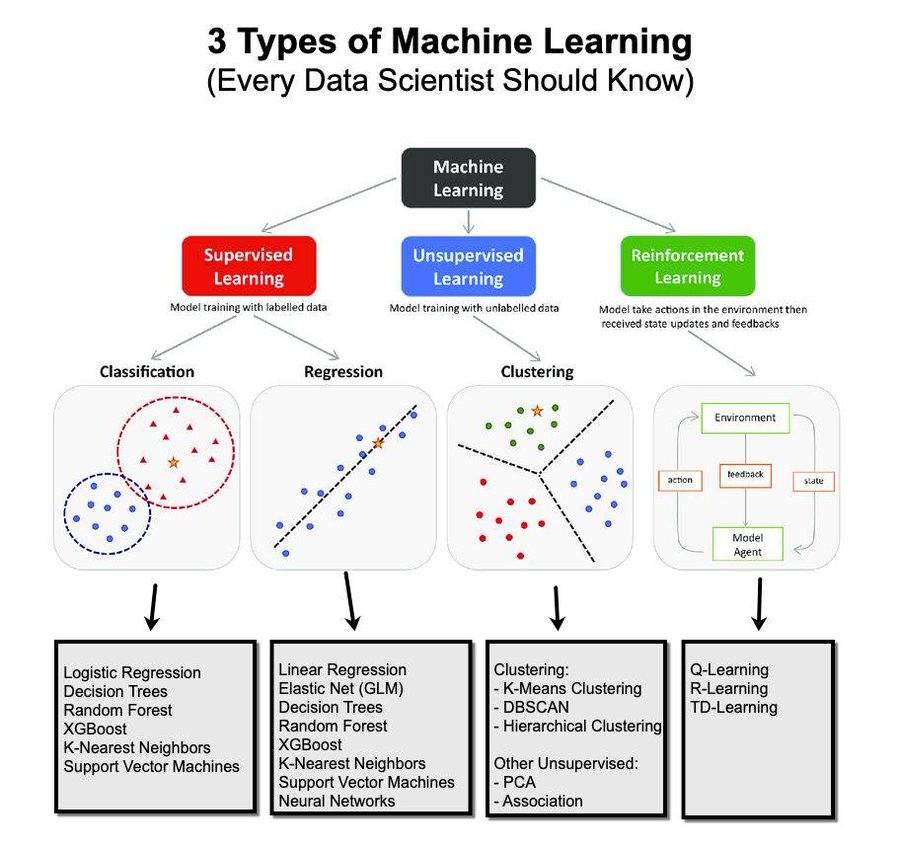
1. Học có giám sát (Supervised Learning)
- 📝 Mô tả: Mô hình được huấn luyện bằng dữ liệu có nhãn, tức là các ví dụ trong dữ liệu đã được gán nhãn để mô hình học cách dự đoán đầu ra dựa trên đầu vào.
- 🔟 Các loại chính:
- ⭐ Classification (Phân loại): Dùng để phân loại dữ liệu vào các nhóm. Ví dụ, một mô hình phân loại email có thể phân loại email là "spam" hoặc "không spam". Các thuật toán phổ biến là Logistic Regression, Decision Trees, Random Forest, XGBoost, K-Nearest Neighbors, và Support Vector Machines.
- ⭐ Regression (Hồi quy): Dùng để dự đoán các giá trị liên tục. Ví dụ, dự đoán giá nhà dựa trên diện tích và vị trí. Các thuật toán thường dùng bao gồm Linear Regression, Elastic Net, Decision Trees, Random Forest, và Neural Networks.
2. Học không giám sát (Unsupervised Learning)
- ⭐ Mô tả: Mô hình học từ dữ liệu không có nhãn, tức là không có thông tin cụ thể nào về nhóm hay kết quả mong muốn trong dữ liệu. Mục tiêu là tìm ra các mẫu hoặc cấu trúc ẩn trong dữ liệu.
- ⭐ Các loại chính:
- ⭐ Clustering (Phân cụm): Nhóm các điểm dữ liệu tương tự nhau vào cùng một cụm. Ví dụ, trong kinh doanh, phân cụm khách hàng thành các nhóm khác nhau dựa trên hành vi mua sắm để có chiến lược marketing phù hợp. Các thuật toán phổ biến là K-Means Clustering, DBSCAN, và Hierarchical Clustering.
- ⭐ PCA và Association: PCA (Principal Component Analysis) được dùng để giảm số chiều của dữ liệu, giúp dễ quan sát và phân tích hơn. Association thường được sử dụng để tìm ra các mẫu hoặc mối quan hệ trong dữ liệu, ví dụ như trong các hệ thống gợi ý sản phẩm.
3. Học tăng cường (Reinforcement Learning)
- ⭐ Mô tả: Mô hình sẽ thực hiện các hành động trong một môi trường và nhận phản hồi (feedback) dưới dạng phần thưởng hoặc hình phạt, từ đó học cách tối ưu hành vi để đạt được phần thưởng cao nhất. Khác với học có giám sát, mô hình không có câu trả lời đúng cho mỗi hành động mà phải tự tìm cách cải thiện dựa trên kinh nghiệm.
- 💡 Ví dụ: Mô hình dạy robot di chuyển trong một phòng chứa chướng ngại vật. Robot sẽ thử di chuyển theo nhiều cách khác nhau và học từ các hành động để tối ưu hóa đường đi sao cho tránh được chướng ngại và đến đích.
- 🤖 Các thuật toán phổ biến: Q-Learning, R-Learning, và TD-Learning.
1. Tổng quan về RAG cho người mới bắt đầu

1.1 Định nghĩa và Khái niệm
-
🤔 RAG là gì?
Tưởng tượng RAG như một thư viện thông minh:
- Bạn hỏi một câu hỏi
- Thủ thư (retriever) tìm những cuốn sách liên quan
- Chuyên gia (LLM) đọc những cuốn sách đó và trả lời câu hỏi của bạn
-
🎯 Tại sao cần RAG?
Ví dụ thực tế:
- Không RAG: "Công ty ABC có bao nhiêu nhân viên?" -> "Tôi không có thông tin cập nhật"
- Có RAG: "Công ty ABC có bao nhiêu nhân viên?" -> "Theo báo cáo mới nhất tháng 3/2024, công ty có 1,500 nhân viên"
-
🔄 So sánh với các phương pháp khác
Ví dụ về trả lời câu hỏi về sản phẩm:
- Fine-tuning: Như dạy cả cuốn sách cho AI -> tốn thời gian, chi phí
- Prompt-engineering: Như ghi chú vào post-it -> giới hạn thông tin
- RAG: Như có thủ thư tìm đúng trang sách cần -> hiệu quả, tiết kiệm
1.2 Kiến trúc cơ bản
-
🏗️ Components chính
Như một nhà hàng:
- Knowledge Base: Kho nguyên liệu (thực đơn, công thức)
- Retriever: Người lấy nguyên liệu
- LLM: Đầu bếp
- Orchestrator: Quản lý nhà hàng
-
🔄 Luồng xử lý
Ví dụ về quy trình đặt món:
- Khách hỏi về món ăn
- Nhân viên tìm thông tin trong thực đơn
- Đầu bếp xem công thức và giải thích cho khách
- Khách nhận được thông tin chính xác về món ăn
-
🤝 Interactions giữa các components
Như một đội bóng:
- Hậu vệ (Retriever): Tìm và chuyền bóng
- Tiền vệ (Orchestrator): Điều phối trận đấu
- Tiền đạo (LLM): Ghi bàn (tạo câu trả lời)
1.3 Ưu và nhược điểm
-
✅ Lợi ích của RAG
Ví dụ thực tế trong CSKH:
- Trả lời chính xác về chính sách mới nhất
- Dẫn nguồn rõ ràng
- Cập nhật thông tin nhanh chóng
-
❌ Hạn chế
Ví dụ về những thách thức:
- Như tìm sách trong thư viện lớn -> có thể chậm
- Như đọc sách không đúng trang -> có thể sai thông tin
- Như thủ thư bận -> đôi khi quá tải
-
🎯 Use cases phù hợp
Ví dụ về ứng dụng hiệu quả:
- Chatbot CSKH: Trả lời về sản phẩm/dịch vụ mới
- Hệ thống tài liệu: Tìm kiếm trong tài liệu kỹ thuật
- Trợ lý nghiên cứu: Tổng hợp thông tin từ nhiều nguồn
-
💡 Mẹo sử dụng:
- Cập nhật knowledge base thường xuyên
- Thiết kế prompt phù hợp
- Monitoring để đảm bảo chất lượng
(cre: một số ý tưởng viết lại dựa trên post của Việt Nguyễn)
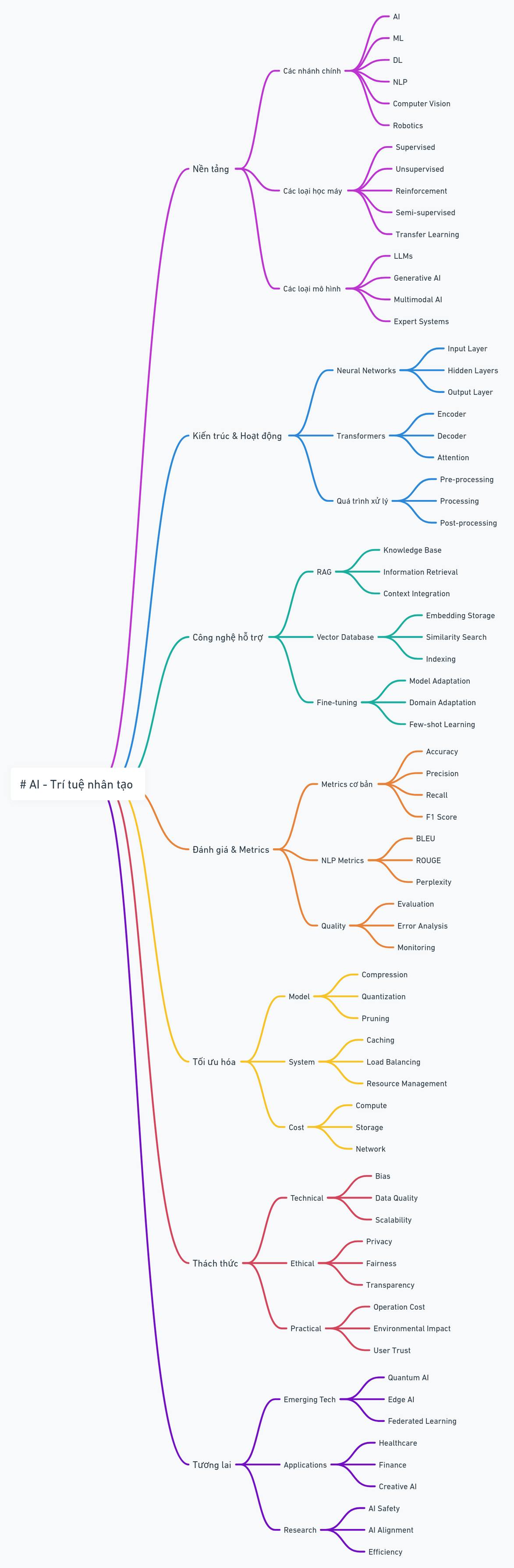
Hình: Bể học ML/AL mênh mông, quay đầu là bờ 🙂