
Nâng Cao Khả Năng Suy Luận trong LLMs: Các Phương pháp và Hướng tiếp cận Triển vọng
Facebook: "https://www.facebook.com/frank.t96/"
Bài phân tích này, dựa trên nghiên cứu "Advancing Reasoning in Large Language Models: Promising Methods and Approaches" của Avinash Patil, sẽ trình bày các phương pháp và hướng tiếp cận hiệu quả để nâng cao khả năng suy luận của LLMs.
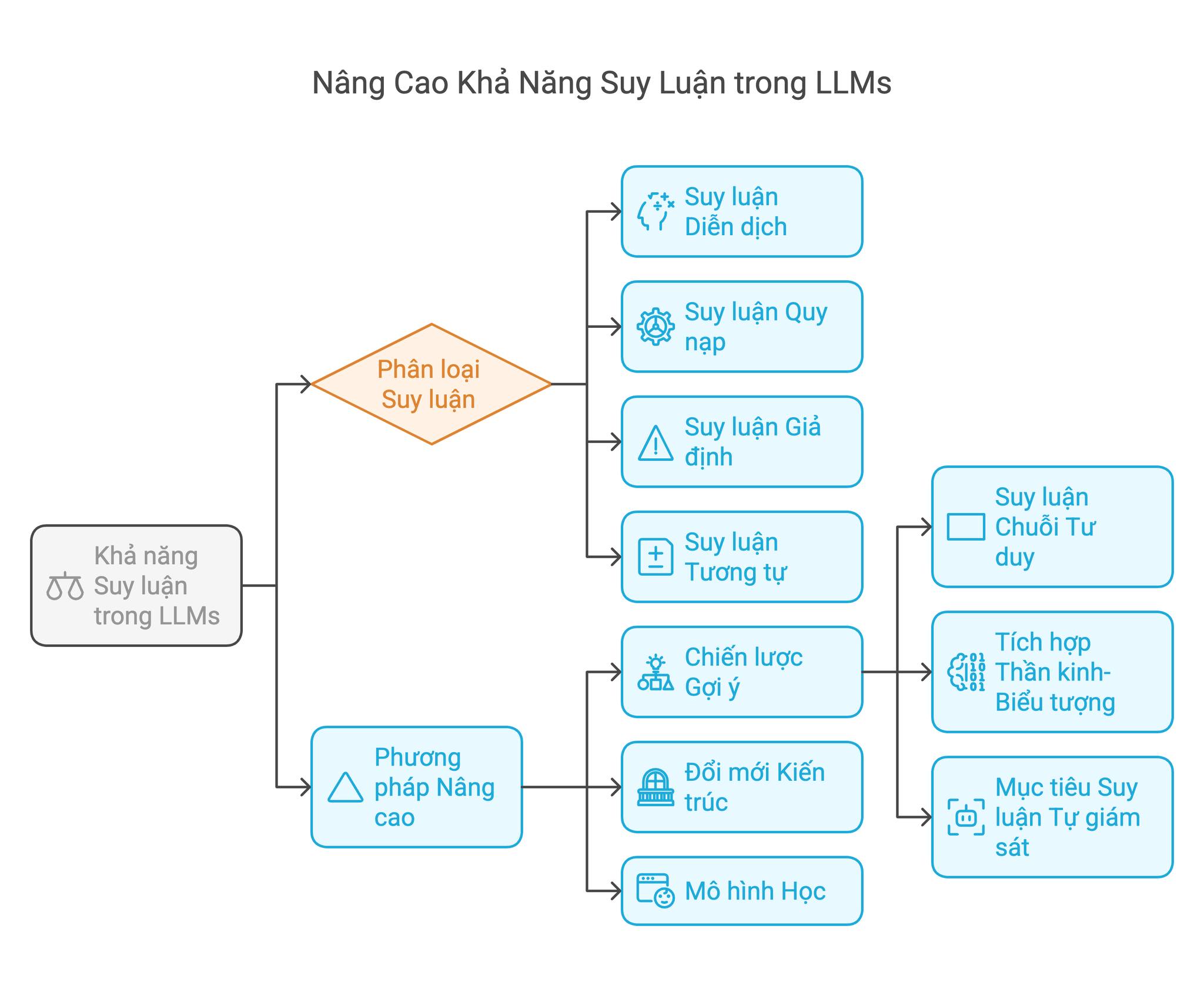
Những tiến bộ gần đây trong các mô hình ngôn ngữ lớn (LLMs) đã cho thấy sự tiến bộ vượt bậc trong nhiều nhiệm vụ xử lý ngôn ngữ tự nhiên, tuy nhiên, khả năng suy luận phức tạp của chúng vẫn là một lĩnh vực nghiên cứu và phát triển tích cực. Báo cáo này tổng hợp các phương pháp hiện đại để nâng cao khả năng suy luận trong LLMs, tập trung vào ba loại phương pháp chính: chiến lược gợi ý (prompting strategies), đổi mới kiến trúc (architectural innovations) và mô hình học (learning paradigms). Bằng cách phân tích các kỹ thuật tiên tiến như suy luận Chuỗi Tư duy (Chain-of-Thought reasoning), tích hợp thần kinh-biểu tượng (neuro-symbolic integration) và mục tiêu suy luận tự giám sát (self-supervised reasoning objectives), đánh giá này xác định những bước đột phá quan trọng và những thách thức dai dẳng trong lĩnh vực này. Bằng chứng thực nghiệm từ các nghiên cứu gần đây cho thấy các phương pháp lai kết hợp gợi ý có cấu trúc với kiến trúc mô-đun mang lại những cải tiến đáng kể nhất, đạt được mức tăng hiệu suất đáng kể so với các phương pháp cơ sở trong các nhiệm vụ suy luận toán học và logic.
Các Khái Niệm Nền Tảng trong Suy Luận LLM
Định Nghĩa Suy Luận trong Hệ Thống Trí Tuệ Nhân Tạo
Suy luận trong LLMs bao gồm khả năng xử lý thông tin một cách có hệ thống, đưa ra suy luận logic và giải quyết vấn đề thông qua các quá trình tư duy có cấu trúc. Không giống như nhận dạng mẫu cơ bản, suy luận nâng cao yêu cầu các mô hình:
- Phân tách các truy vấn phức tạp thành các bước trung gian.
- Duy trì tính mạch lạc theo ngữ cảnh qua nhiều giai đoạn suy luận.
- Áp dụng các quy tắc và ràng buộc logic đặc thù theo miền.
- Xác minh tính nhất quán nội bộ của các giải pháp được tạo ra.
Các chuẩn đánh giá hiện tại cho thấy rằng trong khi các mô hình hiện đại như GPT-4 và LLaMA-2 thể hiện hiệu suất mạnh mẽ trong các nhiệm vụ suy luận bị ràng buộc (ví dụ: các phép toán số học), chúng gặp khó khăn với suy diễn logic mở và suy luận đa bước (multi-hop inference) đòi hỏi tích hợp kiến thức thế giới.
Phân Loại Khả Năng Suy Luận
Các khung đánh giá hiện đại phân loại suy luận LLM thành bốn loại chính: Suy Luận Diễn Dịch (Deductive Reasoning), Suy Luận Quy Nạp (Inductive Reasoning), Suy Luận Giả Định (Abductive Reasoning) và Suy Luận Tương Tự (Analogical Reasoning).
-
Suy Luận Diễn Dịch (Deductive Reasoning) là sự dẫn xuất có hệ thống các kết luận cụ thể từ các tiền đề chung bằng cách sử dụng các quy tắc logic hình thức.
Ví dụ, với tiền đề "Tất cả động vật có vú đều máu nóng" và "Cá voi là động vật có vú", ta có thể suy ra kết luận "Do đó, cá voi là động vật máu nóng". Các mô hình hiện tại đạt được độ chính xác đáng kể trên các chuẩn đánh giá tam đoạn luận tổng hợp, nhưng cho thấy sự suy giảm hiệu suất đáng kể khi các tiền đề chứa các giả định ngầm hoặc yêu cầu kiến thức thế giới.
-
Suy Luận Quy Nạp (Inductive Reasoning) là sự hình thành các nguyên tắc tổng quát từ các quan sát cụ thể. Khả năng này rất quan trọng đối với việc tạo ra giả thuyết khoa học và phát hiện dị thường. Khung SR-FoT chứng minh cách gợi ý có cấu trúc có thể cải thiện độ chính xác suy luận quy nạp đáng kể trong các nhiệm vụ giải quyết vấn đề vật lý.
-
Suy Luận Giả Định (Abductive Reasoning) là suy luận để tìm ra lời giải thích tốt nhất dựa trên thông tin không đầy đủ. LLMs sử dụng các chiến lược suy luận bắt cóc cho thấy triển vọng đặc biệt trong các ứng dụng chẩn đoán và hệ thống phát hiện lỗi. Các triển khai gần đây sử dụng kiến trúc tăng cường truy xuất đã giảm tỷ lệ lỗi đáng kể trong các kịch bản khắc phục sự cố ô tô.
-
Suy Luận Tương Tự (Analogical Reasoning) là xác định và áp dụng sự tương đồng về cấu trúc giữa các miền khác nhau. Chuẩn đánh giá ZebraLogic cho thấy các mô hình hiện tại đạt được độ chính xác đáng kể trong các nhiệm vụ tương tự bằng lời nói, nhưng gặp khó khăn với các phép tương tự không gian-trực quan đòi hỏi suy luận hình học.
Những Tiến Bộ Phương Pháp Luận trong Nâng Cao Suy Luận
Chiến Lược Thiết Kế Gợi Ý (Prompt Engineering Strategies)
-
Suy Luận Chuỗi Tư Duy (Chain-of-Thought - C.o.T) Reasoning. Mô hình C.o.T đã cách mạng hóa suy luận LLM bằng cách yêu cầu rõ ràng các mô hình diễn đạt các bước suy luận trung gian. Như được chứng minh trong chuẩn đánh giá Game of 24, với vấn đề "Sử dụng các số 4, 5, 6 và 8 với các phép toán số học cơ bản để đạt được 24", một giải pháp CoT có thể như sau: đầu tiên, 8 trừ 5 bằng 3, sau đó 6 nhân 3 bằng 18, và 18 cộng 4 bằng 22 (lộ trình không chính xác). Quay lại bước 2, 6 chia 3 bằng 2, sau đó 2 nhân 4 nhân 5 bằng 40 (không chính xác). Một phương pháp thay thế là 8 nhân (5 trừ (6 trừ 4)) bằng 24. Các nghiên cứu thực nghiệm cho thấy C.o.T cải thiện độ chính xác đáng kể đối với các bài toán từ ngữ toán học trong GPT-3.5, với mức tăng lớn hơn được quan sát thấy ở các mô hình lớn hơn. Hiệu quả của kỹ thuật này xuất phát từ sự phù hợp của nó với các quá trình nhận thức của con người, buộc các mô hình phải ngoại hóa các con đường tính toán nội bộ của chúng.
-
Tối Ưu Hóa Tính Tự Nhất Quán (Self-Consistency Optimization). Dựa trên CoT, phương pháp tự nhất quán tạo ra nhiều đường dẫn suy luận thông qua lấy mẫu theo tỷ lệ nhiệt độ và chọn câu trả lời cuối cùng thường xuyên nhất. Phương pháp này giảm thiểu các lỗi chuỗi riêng lẻ, cải thiện độ chính xác suy luận toán học đáng kể trên chuẩn đánh giá GSM8K. Các cân nhắc triển khai chính bao gồm cài đặt nhiệt độ tối ưu (thường là 0,7-1,0), sự đánh đổi chi phí tính toán/thông lượng, và heuristic trích xuất câu trả lời cụ thể theo miền. Việc triển khai Mirascope chứng minh cách xác thực câu trả lời tự động có thể giảm yêu cầu giám sát của con người trong khi vẫn duy trì hiệu suất thủ công cao.
-
Khung Cây Tư Duy (Tree-of-Thought - T.o.T) Frameworks. Kiến trúc T.o.T mở rộng C.o.T bằng cách duy trì nhiều đường dẫn suy luận song song trong cấu trúc đồ thị, cho phép khám phá có hệ thống các không gian giải pháp. Các thành phần chính bao gồm tạo Tư Duy (tạo ra các bước suy luận trung gian đa dạng), Đánh Giá Trạng Thái (chấm điểm các giải pháp một phần bằng cách sử dụng heuristic được học), và Thuật Toán Tìm Kiếm (triển khai các chiến lược BFS/DFS để khám phá đường dẫn tối ưu). Trong việc triển khai Game of 24, T.o.T với tìm kiếm chùm (b=5) đạt tỷ lệ thành công cao hơn so với C.o.T tiêu chuẩn trong GPT-4. Thiết kế mô-đun của khung cho phép tích hợp với các bộ giải thần kinh-biểu tượng để tăng cường sự thỏa mãn ràng buộc.
Đổi Mới Kiến Trúc (Architectural Innovations)
-
Suy Luận Tăng Cường Truy Xuất (Retrieval-Augmented Reasoning). Kiến trúc lai kết hợp truy xuất dày đặc với khả năng tạo ra giải quyết các vấn đề không nhất quán thực tế của LLMs. Khung REALM chứng minh cách tìm nạp kiến thức tích hợp cải thiện độ chính xác suy luận khoa học đáng kể đồng thời giảm tỷ lệ ảo giác.
-
Tích Hợp Thần Kinh-Biểu Tượng (Neuro-Symbolic Integration). Các hệ thống gần đây như Neurosymbolic-LLM kết nối nhận dạng mẫu thống kê với suy luận biểu tượng hình thức thông qua tự động dịch ngôn ngữ tự nhiên thành vị từ logic, tích hợp với các bộ giải SAT và bộ chứng minh định lý, và giao tiếp hai chiều giữa các thành phần thần kinh và biểu tượng. Phương pháp này đạt được độ chính xác cao trong các nhiệm vụ suy luận logic LEGALBench, vượt trội hơn các phương pháp thần kinh thuần túy.
-
Mạng Suy Luận Mô-đun (Modular Reasoning Networks). Việc phân tách LLMs nguyên khối thành các mô-đun con chuyên dụng cho thấy triển vọng đặc biệt đối với các nhiệm vụ suy luận phức tạp. Điều này bao gồm Bộ Phân Tích Cú Pháp (trích xuất các yêu cầu và ràng buộc nhiệm vụ), Bộ Lập Kế Hoạch (tạo ra các bản thiết kế giải pháp từng bước), Bộ Thực Thi (thực hiện các tính toán cụ thể theo miền), và Bộ Xác Minh (kiểm tra tính hợp lệ và tính nhất quán của giải pháp). Khung RAP sử dụng kiến trúc này cho thấy tỷ lệ thành công cao trong các bài toán Blocksworld.
Mô Hình Học (Learning Paradigms)
-
Tinh Chỉnh Cụ Thể Theo Suy Luận (Reasoning-Specific Fine-Tuning). Các bộ dữ liệu được tuyển chọn như MATH-10K và LogicInference-5K cho phép cải thiện có mục tiêu các khả năng suy luận thông qua chiến lược học tập theo chương trình giảng dạy, tăng cường dữ liệu theo hướng phân tích lỗi, và mục tiêu đào tạo tương phản. Các biến thể LLaMA-2 được tinh chỉnh cho thấy sự cải thiện tương đối đáng kể trong các nhiệm vụ suy luận diễn dịch so với các mô hình cơ sở.
-
Học Tăng Cường từ Dấu Vết Suy Luận (Reinforcement Learning from Reasoning Traces). Khung RLR-TR sử dụng dữ liệu ưu tiên của con người về chất lượng suy luận để đào tạo các mô hình phần thưởng, cho phép tạo ra đường dẫn suy luận nhận biết chất lượng, tự động xác định các ngụy biện logic, và tối ưu hóa đa mục tiêu (tính chính xác, hiệu quả, rõ ràng). Các ứng dụng trong tạo bằng chứng toán học cho thấy sự giảm đáng kể các bước nhảy không được hỗ trợ so với tinh chỉnh được giám sát.
Phương Pháp Đánh Giá và Điểm Chuẩn (Evaluation Methodologies and Benchmarks)
Bối Cảnh Đánh Giá Hiện Tại (Current Assessment Landscape)
Bảng Chuẩn tập trung vào các lĩnh vực như Bài Toán Từ Ngữ Toán Học, Suy Luận Logic, Suy Luận Khoa Học và Suy Luận Phức Tạp.
Mô Hình Đánh Giá Mới Nổi (Emerging Evaluation Paradigms)
Các mô hình đánh giá mới nổi bao gồm Kiểm Tra Áp Lực (cố ý đưa ra các tiền đề mâu thuẫn và thông tin gây hiểu lầm để đánh giá tính mạnh mẽ), Chuyển Giao Liên Miền (đo lường sự suy giảm hiệu suất khi áp dụng các mô hình vào các miền mới), Chất Lượng Giải Thích (chấm điểm tự động tính mạch lạc và tính hợp lệ logic của dấu vết suy luận), và Hiệu Quả Tài Nguyên (số lượng FLOPs trên mỗi giải pháp chính xác cho các cân nhắc triển khai thực tế). Chuẩn đánh giá JUSTLOGIC giới thiệu các chiều suy luận, cho thấy các mô hình hiện tại chỉ đạt được độ chính xác trung bình trong các nhiệm vụ suy luận logic toàn diện.
Những Thách Thức Dai Dẳng và Định Hướng Tương Lai (Persistent Challenges and Future Directions)
Giảm Thiểu Ảo Giác (Hallucination Mitigation)
Bất chấp những tiến bộ về kiến trúc, LLMs vẫn tiếp tục tạo ra các tuyên bố không nhất quán về mặt thực tế trong quá trình suy luận. Các phương pháp xác minh tập hợp kết hợp chấm điểm độ tin cậy thần kinh, kiểm tra tính nhất quán biểu tượng, và xác thực kiến thức bên ngoài cho thấy hứa hẹn, giảm tỷ lệ ảo giác đáng kể trong các nhiệm vụ suy luận lâm sàng.
Tổng Quát Hóa Đa Nhiệm Vụ (Cross-Task Generalization)
Các mô hình hiện tại thể hiện phương sai hiệu suất đáng kể trên các loại suy luận. Chuẩn đánh giá MATH-ALL cho thấy độ chính xác cao trong thao tác đại số, độ chính xác trung bình trong chứng minh hình học, và độ chính xác thấp trong tối ưu hóa tổ hợp, điều này cho thấy sự thiếu hụt kiến thức cụ thể theo miền hơn là sự thiếu hụt suy luận tổng quát.
Khung Hợp Tác Con Người-AI (Human-AI Collaboration Frameworks)
Các hệ thống lai kết hợp sự giám sát của con người với suy luận tự động thể hiện hiệu suất vượt trội trong các ứng dụng quan trọng. Trong đó, con người chỉ định các ràng buộc vấn đề và tiêu chí xác minh, LLM tạo ra nhiều ứng cử viên giải pháp, và tinh chỉnh chung được thực hiện thông qua các vòng phản hồi tương tác. Việc triển khai thử nghiệm trong phân tích tài liệu pháp lý cho thấy tiết kiệm thời gian đáng kể với độ chính xác tương đương so với các chuyên gia con người.
Kết Luận (Conclusion)
Sự phát triển của khả năng suy luận trong LLMs thể hiện một trong những biên giới hoạt động tích cực nhất trong nghiên cứu AI. Trong khi các phương pháp hiện tại như gợi ý C.o.T và kiến trúc thần kinh-biểu tượng đã tiến bộ đáng kể so với hiện trạng, những thách thức cơ bản về tính mạnh mẽ, tính tổng quát hóa và khả năng xác minh vẫn tồn tại. Các quỹ đạo hứa hẹn nhất cho sự phát triển trong tương lai dường như nằm ở:
- Kiến Trúc Suy Luận Đa Phương Thức (Multimodal Reasoning Architectures) tích hợp các biểu diễn văn bản, trực quan và biểu tượng.
- Khung Siêu Học Tập (Meta-Learning Frameworks) cho phép thích ứng nhanh chóng với các miền suy luận mới.
- Thiết Kế Lấy Tính Giải Thích Làm Trung Tâm (Explainability-Centric Design) ưu tiên tạo ra dấu vết suy luận minh bạch.
- Chiến lược Triển Khai Tiết Kiệm Năng Lượng (Energy-Efficient Deployment) cho các ứng dụng trong thế giới thực.
Như đã được chứng minh bởi những cải tiến hiệu suất đạt được thông qua các phương pháp lai trong các chuẩn đánh giá gần đây, sự kết hợp chiến lược giữa các chiến lược gợi ý, đổi mới kiến trúc và mô hình học tiên tiến có khả năng thúc đẩy thế hệ hệ thống AI có khả năng suy luận tiếp theo. Tuy nhiên, việc đạt được tính linh hoạt suy luận ở cấp độ con người sẽ đòi hỏi những đột phá trong tổng quát hóa thành phần và tích hợp mô hình thế giới vẫn còn khó nắm bắt với các phương pháp hiện tại.